Benchmarks
brinicle is designed for constrained environments where loading a full index into RAM is not practical. These benchmarks demonstrate brinicle’s performance characteristics across different scenarios.Low-RAM Benchmark (MNIST 60K)
In a 256MB RAM / 1 CPU container on MNIST 60K vectors (784 dimensions), brinicle passes while several popular vector databases fail due to out-of-memory errors:| System | Outcome |
|---|---|
| brinicle | ✅ PASS |
| chroma | ✅ PASS |
| qdrant | ❌ OOMKilled |
| weaviate | ❌ OOMKilled |
| milvus | ❌ OOMKilled |
SIFT 1M Benchmark
On SIFT 1M vectors (128 dimensions), using the same in-process deployment model as FAISS and hnswlib, brinicle achieves competitive recall and latency:| System | Build (s) | Recall@10 | Avg Latency (ms) | QPS |
|---|---|---|---|---|
| FAISS | 237.282 | 0.96999 | 0.092 | 10,857.43 |
| hnswlib | 241.301 | 0.96364 | 0.093 | 10,711.86 |
| brinicle | 243.750 | 0.96989 | 0.103 | 9,730.65 |
Analysis
- Build Time: brinicle’s build time is within 3% of FAISS and hnswlib, which is excellent for a disk-first engine.
- Recall@10: brinicle achieves 0.970 recall, matching FAISS and slightly exceeding hnswlib.
- Latency: brinicle’s average latency is about 12% higher than FAISS and hnswlib, which is the expected trade-off for disk-backed operation.
- QPS: brinicle achieves about 90% of the throughput of FAISS and hnswlib while keeping the index on disk.
Understanding the Results
Why brinicle is Competitive
Traditional in-memory HNSW implementations like FAISS and hnswlib load the entire index into RAM, which provides the lowest possible latency. brinicle’s disk-first approach means that graph traversal involves disk I/O, which is inherently slower than RAM access. However, brinicle mitigates this through:- Smart caching — Frequently accessed graph nodes are cached in memory
- Optimized I/O — Sequential read patterns minimize disk seek time
- Graph structure optimization — The HNSW graph is structured to minimize the number of disk accesses per query
When brinicle Excels
brinicle excels in scenarios where:- RAM is limited — In constrained environments, brinicle works where others fail
- Cost optimization — You can run brinicle on cheaper, low-RAM instances
- Edge deployment — brinicle runs on resource-constrained edge devices
- Dataset size vs. RAM — When your dataset doesn’t fit in available RAM
When to Consider Alternatives
brinicle may not be the best choice when:- Maximum throughput is required — If you need the absolute highest QPS and have ample RAM, in-memory solutions like FAISS may be faster
- Very large datasets — brinicle is designed for datasets under 10M vectors; for larger datasets, distributed vector databases may be more appropriate
- Real-time requirements — If sub-millisecond latency is required, in-memory solutions have an inherent advantage
Reproducing Benchmarks
You can reproduce these benchmarks using the brinicle repository:Memory Usage
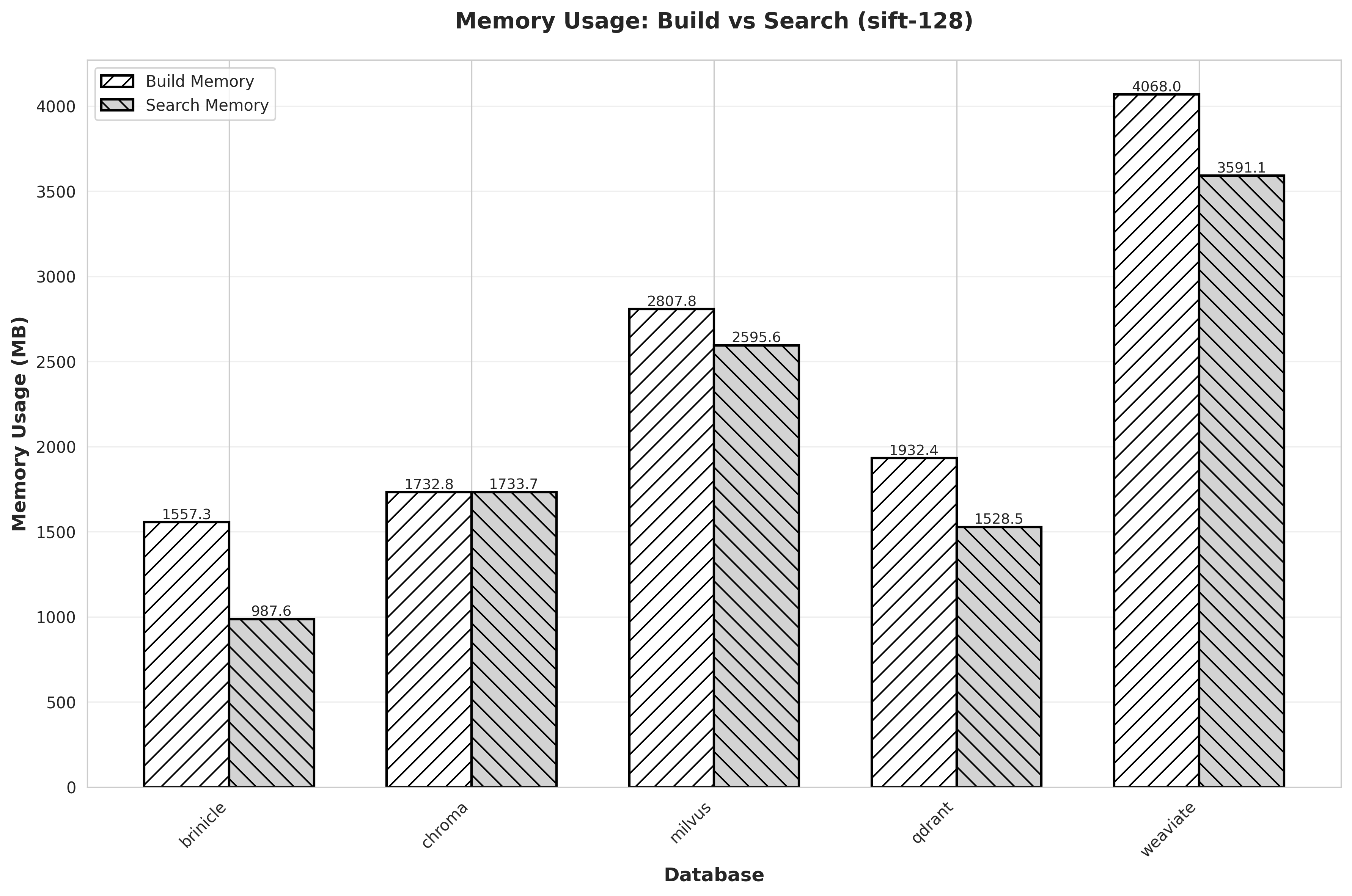 brinicle’s memory usage is significantly lower than in-memory vector databases because it keeps the index on disk and only loads the portions needed for the current query. This allows brinicle to operate in environments with very limited RAM while still providing competitive search performance.
brinicle’s memory usage is significantly lower than in-memory vector databases because it keeps the index on disk and only loads the portions needed for the current query. This allows brinicle to operate in environments with very limited RAM while still providing competitive search performance.